大数据如何入门 从数据科学概论到避开学习误区,聚焦计算机系统服务视角
在数字化浪潮席卷全球的今天,大数据已成为驱动技术创新、商业决策与社会发展的核心引擎。对于许多希望进入这一领域的初学者而言,常常会感到迷茫:大数据到底该怎么学?本文将从数据科学的基本概论入手,剖析常见的学习误区,并特别结合“计算机系统服务”这一关键领域,为你勾勒出一条清晰的学习路径。
一、 数据科学概论:理解大数据的核心内涵
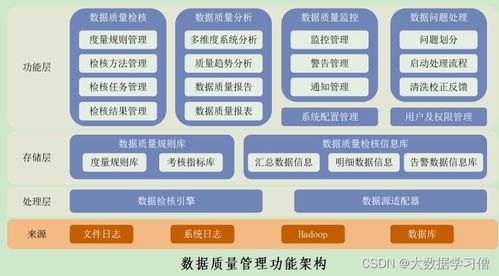
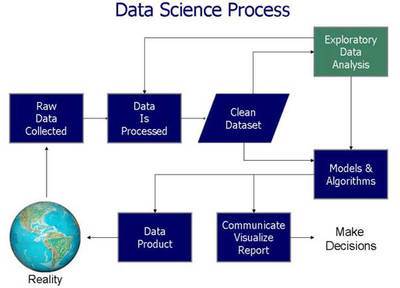
数据科学是一个跨学科的领域,它融合了统计学、计算机科学、领域专业知识(如金融、生物、工程等),旨在从海量、高维、多源的数据中提取有价值的信息和洞见。其核心流程通常包括:
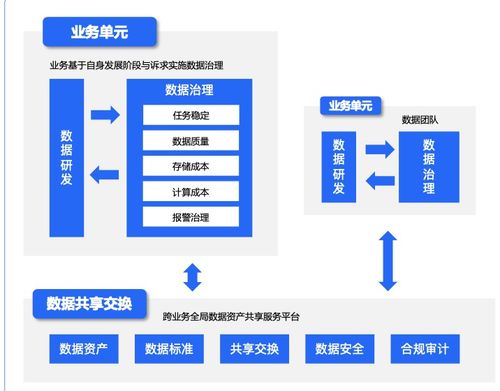
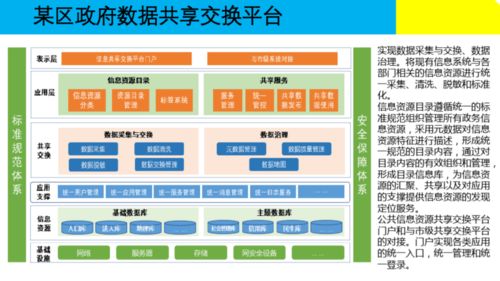
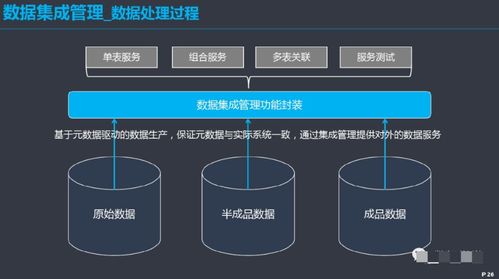
- 数据采集与存储:这是基础。大数据往往来源于日志文件、传感器、社交媒体、交易记录等。学习如何从不同源头(包括通过“计算机系统服务”如API接口、网络爬虫、数据库连接)高效获取数据,并利用分布式存储系统(如HDFS)或云存储服务进行管理至关重要。
- 数据清洗与预处理:原始数据通常充满“噪音”。掌握数据清洗、转换、集成和规约技术,是保证后续分析质量的前提。这涉及到大量的编程和脚本编写工作。
- 数据分析与建模:运用统计学方法、机器学习算法对数据进行探索、分析和建模,发现模式、趋势或进行预测。这是数据科学最具创造性的部分。
- 数据可视化与解释:将分析结果以直观的图表、仪表盘等形式呈现,并能够用业务语言解释其意义,驱动决策。
理解这个流程,是学习大数据的第一个关键步骤。
二、 常见的大数据学习误区
在学习过程中,许多初学者容易陷入以下误区:
- 重工具,轻基础:热衷于学习Hadoop、Spark等流行框架,却忽视了计算机科学基础(数据结构、算法、操作系统、网络)和数学基础(线性代数、概率论、统计学)。没有扎实的根基,很难深入理解工具背后的原理,遇到复杂问题时会束手无策。
- 重算法,轻工程:痴迷于研究最前沿、最复杂的机器学习模型,却忽略了数据工程的重要性。在实际工作中,数据管道构建、系统稳定性、代码可维护性、性能优化等工程能力往往比模型本身的微小精度提升更为关键。
- 重技术,轻业务:脱离具体应用场景和业务问题学习技术。大数据技术的价值最终要体现在解决实际问题上。不了解业务逻辑和领域知识,分析结果可能毫无意义。
- 追求“大而全”,忽视“小而精”:试图一次性掌握所有技术栈。建议从一个核心领域(如数据处理或一个特定分析方向)深入,再逐步拓宽。
三、 聚焦“计算机系统服务”:构建坚实的技术底座
“计算机系统服务”是支撑大数据技术落地的底层基础设施。从这一视角出发,能帮助你建立更系统、更工程化的学习思维。应重点关注:
- 操作系统与网络:深入理解Linux系统管理、进程调度、内存管理、文件系统以及TCP/IP网络协议。大数据集群(如Hadoop/Spark集群)的管理、性能调优和故障排查都建立在此基础之上。
- 分布式系统原理:这是大数据技术的灵魂。学习分布式计算模型、一致性协议(如Paxos、Raft)、容错机制、数据分片与复制等核心概念。理解这些,才能看懂HDFS、HBase、Kafka等系统的设计思想。
- 存储与计算服务:
- 存储服务:掌握分布式文件系统(HDFS)、对象存储(如AWS S3)、NoSQL数据库(如HBase、Cassandra)和NewSQL数据库的原理与使用。
- 计算服务:精通批处理框架(如MapReduce, Spark Core)、流处理框架(如Spark Streaming, Flink)和资源调度框架(如YARN, Kubernetes)。理解它们如何协同工作,构成完整的数据处理流水线。
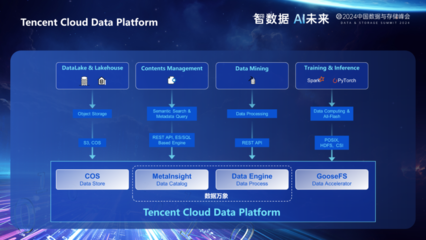
- 云服务与DevOps:现代大数据平台日益云化。学习如何使用AWS、Azure或阿里云等提供的大数据托管服务(如EMR、Databricks),并掌握CI/CD、容器化(Docker)、编排(Kubernetes)等DevOps实践,以实现高效、自动化的系统部署与运维。
四、 循序渐进的学习路径建议
- 第一阶段:筑牢基石
- 计算机基础:熟练掌握一门编程语言(Python或Scala是主流选择),复习数据结构和算法。
- 数学与统计:学习线性代数、概率论与数理统计。
- 数据库知识:精通SQL,理解关系型数据库原理。
- 第二阶段:入门核心
- Linux与网络:熟练使用Linux命令行,理解基本网络配置。
- 分布式基础:阅读《数据密集型应用系统设计》等经典书籍,建立分布式思维。
- Hadoop生态入门:学习HDFS、MapReduce、YARN、Hive的核心概念与基本操作。
- 第三阶段:深化与实践
- 深入计算框架:系统学习Spark(包括RDD/DataFrame API、Spark SQL、Streaming)。
- 拓宽技术栈:根据兴趣,选择学习实时计算(Flink)、消息队列(Kafka)、协调服务(ZooKeeper)或一个NoSQL数据库。
- 机器学习应用:学习使用Spark MLlib或Scikit-learn进行基本的机器学习建模。
- 项目实战:在本地或云环境搭建小型集群,完成一个端到端的数据分析或处理项目,涵盖数据采集、清洗、分析、可视化的全流程。
- 第四阶段:融合与精进
- 云原生大数据:深入学习在Kubernetes上部署和管理大数据应用,或使用云平台托管服务。
- 系统调优与架构:学习性能 profiling、JVM调优、Spark/Flink作业优化,并尝试设计满足特定需求的大数据系统架构。
- 领域结合:将技术应用于一个具体的垂直领域(如推荐系统、风控、物联网数据分析)。
###
学习大数据是一场马拉松,而非短跑。它要求学习者兼具“深度”与“广度”:既要有扎实的计算机系统与数学基础作为“深度”支撑,又要对快速演进的技术生态保持“广度”上的关注。从理解数据科学的工作流开始,警惕常见的学习误区,并特别重视“计算机系统服务”所代表的底层工程能力,你就能构建起属于自己的、坚实的大数据知识体系,最终将数据转化为真正的价值。
如若转载,请注明出处:http://www.chinaapmdata.com/product/63.html
更新时间:2026-06-19 10:30:03