基于Python的农产品价格数据分析与可视化系统设计与实现 数据处理模块

在现代农业经济管理中,农产品价格数据分析对于生产者、经销商、政策制定者及消费者均具有重要意义。一个高效、直观的数据分析与可视化系统能够帮助各方洞察市场趋势、预测价格波动、优化资源配置。本文聚焦于基于Python的农产品价格数据分析与可视化系统的核心环节——数据处理模块的设计与实现。
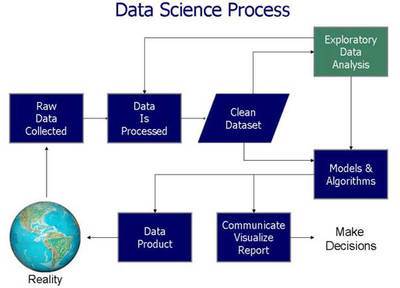
一、数据处理模块的核心地位与目标
数据处理是整个系统的基础与前提。原始农产品价格数据通常来源于多个渠道(如政府公开数据、农业市场平台、电商平台API等),具有多源、异构、可能包含噪声与缺失值等特点。因此,数据处理模块的核心目标在于:
- 数据集成与清洗:将来自不同源的数据进行整合,统一格式与标准,并处理缺失值、异常值及重复记录。
- 数据转换与规约:将原始数据转换为适合分析的格式(如时间序列),并进行必要的特征工程(如计算同比、环比、移动平均等衍生指标)。
- 数据存储与管理:设计高效、可扩展的数据存储方案,便于后续的分析与可视化模块快速调用。
二、关键技术栈与工具选择
Python生态为此提供了强大的支持:
- 数据获取与处理:
requests、BeautifulSoup/Scrapy(用于网络爬虫),pandas(核心数据处理库)。 - 数据存储:轻量级方案如SQLite、CSV文件;中大型方案可选用MySQL、PostgreSQL或MongoDB。
pandas与SQLAlchemy库能便捷地进行数据库交互。 - 辅助工具:
NumPy用于数值计算,datetime模块处理时间数据。
三、数据处理流程设计与实现
1. 数据采集与导入
系统支持多种数据导入方式:
- API接口调用:对于提供规范API的数据源(如部分农业数据平台),使用
requests库定时获取JSON或XML格式数据。
- 网络爬虫:对于无API的网页数据,设计定向爬虫,利用
BeautifulSoup解析HTML,提取表格或列表中的价格、日期、品类等信息。
- 本地文件读取:支持从Excel(
.xlsx)、CSV(.csv)等常见格式文件直接导入。使用pandas的read<em>csv、read</em>excel函数可轻松实现。
2. 数据清洗与预处理
这是保证数据质量的关键步骤,主要利用pandas的DataFrame进行操作:
- 缺失值处理:根据业务逻辑,采用向前填充(
ffill)、向后填充(bfill)、均值/中位数填充或直接删除。
- 异常值检测与处理:通过统计方法(如3σ原则)或业务规则(如价格不可能为负或极端高)识别异常值,并进行修正或剔除。
- 格式标准化:统一日期时间格式(
pd.to_datetime)、价格单位(如统一为“元/公斤”)、农产品品类名称(建立映射词典)等。
- 去重:删除完全重复的记录,或基于关键字段(如日期、品类、市场)进行去重。
3. 数据转换与特征工程
将清洗后的数据转换为更有分析价值的形式:
- 时间序列化:将数据按日期和农产品品类设置为索引,形成规整的时间序列数据,便于进行趋势、季节性分析。
- 衍生特征计算:利用
pandas的shift、rolling、pct_change等方法,计算诸如日环比、周同比、月均价、N日移动平均线等关键指标。
- 数据结构重塑:为满足不同可视化图表(如热力图、对比柱状图)的需求,可能需要进行数据透视(
pivot_table)或融合(melt)操作。
4. 数据存储与接口设计
处理后的高质量数据需要持久化存储:
- 数据库设计:设计至少包含
产品基础信息表(品类、规格等)、市场价格记录表(日期、市场、品类、价格)等核心表结构。
- 数据入库:使用
pandas的to_sql方法或结合SQLAlchemyORM框架,将DataFrame写入数据库。
- 缓存机制:对于频繁访问的聚合数据(如最近一周各品类均价),可使用内存缓存(如
Redis)或pandas的HDF5格式文件进行加速。
- 提供数据接口:封装数据查询函数或类,为后续的分析和可视化模块提供简洁的API,例如
get<em>price</em>series(product, start<em>date, end</em>date)。
四、实践要点与优化建议
- 自动化与调度:利用
crontab(Linux)或schedule库(Python)实现数据采集、清洗、入库的全流程自动化定时任务。 - 错误处理与日志记录:在数据采集和清洗环节加入健壮的错误处理(
try-except)和详细的日志记录(logging模块),便于系统监控和故障排查。 - 模块化设计:将数据采集、清洗、存储等功能封装为独立的类或模块,提高代码可读性、可维护性和可测试性。
- 性能考量:对于大规模历史数据,使用
pandas的向量化操作替代循环,并适时利用Dask库进行并行处理以提升效率。
###
数据处理模块作为农产品价格数据分析与可视化系统的“基石”,其设计与实现的优劣直接决定了上层分析与可视化结果的质量与可靠性。通过合理运用Python强大的数据处理生态,构建一个高效、稳定、可扩展的数据处理流水线,能够为揭示农产品市场价格规律、支撑农业相关决策提供坚实、干净的数据基础,最终使系统的价值得以充分发挥。
如若转载,请注明出处:http://www.chinaapmdata.com/product/40.html
更新时间:2026-06-19 19:17:56